The 7 levels of AI
Spanish translation: https://tinyurl.com/7levelsofAISpanish
New: I decided it was time (March, 2026) to recognize the power of modern large language models (widely referred to as “AI”) when combined with decision-making tools. I have long made the point that LLMs cannot “make” decisions (that is, choose the best from a set of choices according to some set of metrics) - decision-making requires the analytics that fall broadly under the umbrella of “optimization.” But LLMs can perform a variety of functions that make optimization models much more useful in the real world.
I have updated my original set of “7 levels of AI” where level 7 was capabilities such as creativity, reasoning, and judgment that I consider to be beyond any computer. In the new version, I use level 7 to refer to what I am now calling the next generation of AI, where large language models and other pattern-matching technologies from machine learning are integrated with optimization technologies.
This produces the 7 levels of artificial intelligence shown below. These can be organized into three groups:’
- Group 1 - Levels 1-4 - These are trying to make computers behave like humans. Level 1 is typically user-specified rules, while levels 2, 3 and 4 are all some form of machine learning.
- Group 2 - Levels 5-6 - These are the decision-making layers that fall under the umbrella of optimization. Level 5 covers (static) deterministic optimization, while level 6 captures sequential decision problems which all involve making decisions in the presence of some form of uncertainty. Levels 5 and 6 often depend on statistical estimation (level 2), but may draw on information derived from levels 3 (image processing) and 4 (large language models and other forms of “generative AI”).
- Group 3 - Level 7 - Here, we combine the power of large language models and optimization models. LLMs offer tremendous tools for interfacing between computer models and the real world, whether it is interpreting complex data, talking to people, or helping people understand the results. Optimal Dynamics has named these combined systems “decision-native agentic systems” to describe the integration of optimization within a web of agents from the first four levels.

Previously I let level 7 handle the most aspirational claims of intelligence such as creativity and judgment. It is my belief that at the end of the day, machines are here to serve people, and there will be activities that can only be done by people. Dreams of a world that is entirely run by machines fail to recognize that machines are never going to be able to set goals and creative initiatives that promote these goals. I still call this “science fiction” but no longer give it a level.
**Level 1) Rule-based logic **
Rule-based logic (alternatively, “symbolic rule-based reasoning”) was the first form of “AI” that emerged in the 1960s and 1970s, and produced the initial surge of interest in what computers could do. As computers became more powerful in the 1980s, this logic was captured by “expert systems.”
Rule-based logic involves rules specified by a human, coded into logic. Simple examples include “if you are eating red meat, then drink red wine,” but the number of cases quickly exploded as occurred in health: “a male patient, over 60, with high blood sugar, not a smoker, no parents with diabetes, …, should follow this [multidimensional] diet.”
Rule-based logic did not come close to meeting the early expectations of AI, but far from being a complete failure (as it was once viewed), rule-based logic is used throughout modern machine intelligence. There are a number of commercial “rules engines” available today which are widely used.
**Level 2) Basic machine learning **
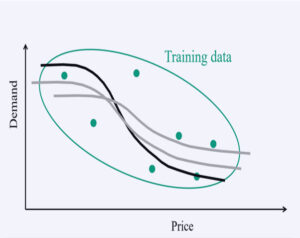 This covers well-known statistical models using lookup tables, parametric models (including linear or nonlinear models and neural networks) or nonparametric models. These methods first emerged in the early 1900s under the umbrella of statistics, but grew dramatically as computers became more powerful (computer scientists entered the field using the name “machine learning”). The most popular models were linear (in the parameters), capturing basic relationships between input variables (also known as explanatory or independent variables, or “covariates”) and a response. For example, we might use price with variations such as price-squared and log of price as inputs, to predict the response of the demand. These models matured with the introduction of nonlinear models (such as logistic regression and early neural networks), and nonparametric models (using local approximations). Neural networks have been popular since the 1970s, and widely used in many nonlinear (deterministic) estimation problems.
This covers well-known statistical models using lookup tables, parametric models (including linear or nonlinear models and neural networks) or nonparametric models. These methods first emerged in the early 1900s under the umbrella of statistics, but grew dramatically as computers became more powerful (computer scientists entered the field using the name “machine learning”). The most popular models were linear (in the parameters), capturing basic relationships between input variables (also known as explanatory or independent variables, or “covariates”) and a response. For example, we might use price with variations such as price-squared and log of price as inputs, to predict the response of the demand. These models matured with the introduction of nonlinear models (such as logistic regression and early neural networks), and nonparametric models (using local approximations). Neural networks have been popular since the 1970s, and widely used in many nonlinear (deterministic) estimation problems.
Level 3) Pattern recognition using deep neural networks
 The research community has studied neural networks since the 1960s, but it was the use of deep neural networks, along with the availability of large datasets, starting around 2010, that produced the first true breakthroughs in pattern recognition. This was the foundation of the modern use of “AI” when it emerged in the 2010s for voice recognition, facial recognition, and image identification.
The research community has studied neural networks since the 1960s, but it was the use of deep neural networks, along with the availability of large datasets, starting around 2010, that produced the first true breakthroughs in pattern recognition. This was the foundation of the modern use of “AI” when it emerged in the 2010s for voice recognition, facial recognition, and image identification.
Pattern recognition using deep neural networks is just another form of nonlinear modeling, but it took machine learning into an entirely new class of applications, bringing a level of visibility to the field of machine learning far beyond what had been achieved with the work described under level 2.
**Level 4) Large language models **
 Learning speech patterns using ultra-deep neural networks burst into the public imagination in 2023 with the introduction of ChatGPT building on research that has been evolving since the 2000s (but especially post 2010).
Learning speech patterns using ultra-deep neural networks burst into the public imagination in 2023 with the introduction of ChatGPT building on research that has been evolving since the 2000s (but especially post 2010).
Although large language models can be viewed as merely an extension of deep neural networks for pattern recognition, I have reserved an entire level for this application given the dramatic increase in the complexity of language problems (LLMs require substantially more data preparation), and the sheer growth in the size of neural networks (and the training datasets to train them) used to support this problem setting. Unlike pattern recognition, where the “answer” to “what is this pattern” is deterministic, LLMs deal with much richer inputs and can produce a range of outputs to a single query (which means it has a stochastic response). Some people equate its ability to create its own sequences of words and phrases, but it is nothing more than randomization among patterns found in the training dataset.
LLMs (such as ChatGPT) are often associated with a much broader category known as “artificial general intelligence” which includes more general forms of learning for unstructured problems. I put these capabilities in Level 7. I limit Level 4 to technologies that have to be trained, which implies it is still a form of supervised learning. This means that LLMs will always produce words and phrases that have been used in the training datasets. It is for this reason that companies supporting this technology are investing heavily not just in the training using massive datasets, but also in the active use of people to guide the behavior of the neural network.

There has been a lot of hype about the potential danger of LLMs. The only danger of an LLM is misinformation, which means any damage is still coming from people. There is, of course, no shortage of misinformation on the internet today, so we can hope that modern society has developed defenses to misinformation, but it is something that we have to be aware of.
**Level 5) Deterministic optimization **
Unlike machine learning models, deterministic optimization depends on an explicit model of a problem that includes both the physics of the problem as well as a performance metric. Inputs to the model include controllable parameters, also known as actions or decisions. Sophisticated algorithms are used to search over feasible regions to optimize the performance metrics.
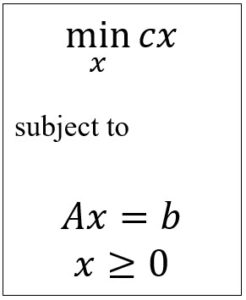 Unlike machine learning-based technologies (levels 2-4) which have to be trained using a training dataset, deterministic optimization does not involve any training. Instead, it uses a model of a problem that captures the physics of the underlying application, along with a performance metric that allows us to evaluate decisions. Then, algorithms are used to search for the best decision that is implementable, and which optimizes the specified performance metric. For example, in the 1990s tools emerged for scheduling airlines that were able to produce more efficient schedules. There are countless examples of achievements like this from the operations research community.
Unlike machine learning-based technologies (levels 2-4) which have to be trained using a training dataset, deterministic optimization does not involve any training. Instead, it uses a model of a problem that captures the physics of the underlying application, along with a performance metric that allows us to evaluate decisions. Then, algorithms are used to search for the best decision that is implementable, and which optimizes the specified performance metric. For example, in the 1990s tools emerged for scheduling airlines that were able to produce more efficient schedules. There are countless examples of achievements like this from the operations research community.
One class of deterministic optimization problems arises in machine learning. The problem is to find the best set of parameters that minimizes the difference between a parameterized function (often called a model) and a set of observations (the training data set). Using a neural network to solve a problem (which requires solving the optimization problem of fitting the neural network to the training dataset), versus using an optimization model to optimize some problem (model-based optimization) are often confused, but they are fundamentally different.
Model-based optimization, unlike training-based machine learning, is able to produce solutions that are better than what any human can achieve. The price of this performance is that we have to invest the time to create a model of the physical problem inside the computer. Note that a neural network does not directly capture the physics of a problem; instead, it tries to learn appropriate behaviors through the training dataset.
A major difference between a statistical model (such as a neural network) and an optimization model is the objective function. The objective when fitting a statistical model to a training dataset is always one of minimizing some distance metric (such as the sum of the squares of the difference between the model and the training dataset). By contrast, optimization models require that an objective function be specified by the analyst, in addition to the constraints that capture the properties of a problem.
**Level 6) Sequential decision problems **
Here we are solving a problem that consists of the sequence
*decision, information, decision, information,… *
where decisions have to be made given the uncertainty of information that has not yet arrived. The optimization problem is to find the best method for making decisions (known as a policy). Special cases of sequential decision problems include:
decision, information (this describes classical stochastic search problems)
and
decision, information, decision (this describes two-stage stochastic programming problems).
More general problems have sequences of “decision, information” that extend over either a finite or infinite horizon.
![The sequential decision objective: max over π of E [ Σ from t=0 to T of C(S_t, X^π(S_t)) | S_0 ]](/assets/images/the-7-levels-of-ai/7levelsofAI6-300x114.jpg) While deterministic optimization problems search for the best decision \(x\) (which is typically a vector), sequential decision problems require searching for a function \(X^\pi(S_t)\) known as a policy (designated “\(\pi\)”), which is a function that maps the information in the state variable \(S_t\) to a decision. For sequential decision problems, a decision might be binary, discrete, scalar continuous, or any type of vector. The challenge is that the policy has to work well over time, according to some metric (typically an expectation, which means we are optimizing the performance on average).
While deterministic optimization problems search for the best decision \(x\) (which is typically a vector), sequential decision problems require searching for a function \(X^\pi(S_t)\) known as a policy (designated “\(\pi\)”), which is a function that maps the information in the state variable \(S_t\) to a decision. For sequential decision problems, a decision might be binary, discrete, scalar continuous, or any type of vector. The challenge is that the policy has to work well over time, according to some metric (typically an expectation, which means we are optimizing the performance on average).
 The AI community (in computer science) studies this problem under the banner of “reinforcement learning” but there are approximately 15 distinct fields, each with one or more books, using eight different notational systems. This diversity reflects the tremendous richness of sequential decision problems. A library of materials on “sequential decision analytics” is contained here.
The AI community (in computer science) studies this problem under the banner of “reinforcement learning” but there are approximately 15 distinct fields, each with one or more books, using eight different notational systems. This diversity reflects the tremendous richness of sequential decision problems. A library of materials on “sequential decision analytics” is contained here.
Sequential decision problems represent a significant extension of deterministic optimization models. Like deterministic optimization, sequential decision problems require modeling the physics and dynamics of a problem and include a performance metric that allows us to identify the best decisions. Solving SDPs often uses machine learning, but like deterministic optimization, searching for policies does not require a training dataset. For this reason, SDPs can produce behaviors that outperform people. This is how computer science was able to create programs for playing chess and Computer Go that would outperform trained experts. Other applications can be found in optimal control (such as landing SpaceX) and optimizing fleets of trucks.
Levels 5 and 6, which are both a form of optimization, can produce tools that outperform humans. Such problems may be quite complex, either due to size (such as planning an airline schedule), or because of the inherent complexity of sequential decision problems. However, these are for well-structured problems with properties that can be fully specified by a mathematical model.
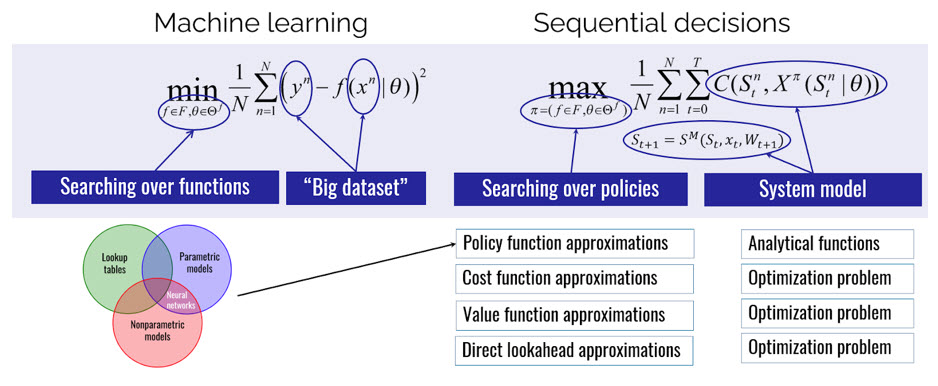
We put sequential decision problems into their own level because they require a fundamentally different way of thinking about optimization problems. Instead of determining a single vector \(x\), we now have to search over functions (known as “policies”), just as we do in machine learning. However, policies for sequential decision problems fall into four fundamental classes:
- Policy function approximations (PFAs) – These are functions that map information in the state variable to a decision.
- Cost function approximations (CFAs) – These are parameterized versions of (typically deterministic) optimization models.
- Value function approximations (VFAs) – These are the policies based on approximations of Bellman’s equation. This is what most people associate with reinforcement learning (also known as approximate dynamic programming).
- Direct lookahead approximations (DLAs) – These policies are based on solving approximate lookahead models.
The first class, PFAs, includes every function that might be used for machine learning, including lookup tables, linear or nonlinear models (including neural networks), and nonparametric models. Hybrid policies can be created from combinations of two, three, and even all four of the policies above.
The slide below compares machine learning (on the left) to sequential decision problems (on the right). Machine learning searches for the best function (the statistical model) to match a training dataset. Sequential decision problems also search over functions (policies) to optimize some performance metric, given a transition function that describes how the state variable evolves over time. While machine learning searches over three types of functions (lookup tables, parametric models, and nonparametric models), sequential decision problems search over four classes of policies, where the first class includes any function that might be used for machine learning.
Level 7) Integrated LLMs and decisions
Optimization models are incredible technologies in terms of returning optimal (or at least optimized) decisions under very complex settings. However, the sophisticated research into models and algorithms depends on:
a. Getting the data into the model. b. Accurately representing the physics of the problem. c. Communicating the results to the field so they can be implemented.
Each of these depends on interacting with people, or datasets that contain complex (and often imperfect) information about a system.
The graph below depicts the flow of information along the yellow paths from the field into a data repository, possibly using large language models to help with the process, and sometimes using machine learning tools to estimate quantities and parameters that are not known.
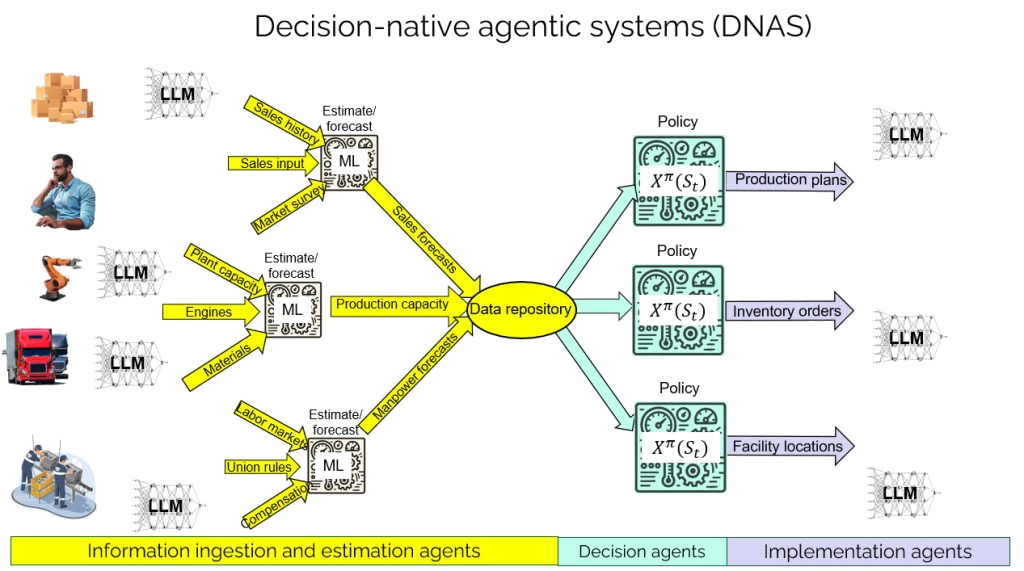
The information ultimately ends in a data repository that is then input to the functions (policies) that are used to make various decisions (shown in green). Then the decisions (in blue) are communicated to the field, possibly using more LLMs to help people understand the results.
Notes:
- I chose three levels of artificial intelligence, 2, 3 and 4, that all involve supervised machine learning, and all three may include the use of neural networks. This raises the question of why these are at different levels. The reason is that the machine learning technologies, and most specifically the use of neural networks, are on completely different levels, from basic neural networks to deep neural networks used in pattern recognition, to the ultra-deep networks used in large language models.
- Even more important is the dramatic difference between the problems that are being considered. Level 2 is the familiar set of estimation problems that have been studied since the early 1900s. By contrast, level 3 addresses a variety of pattern recognition problems that exhibit a structure completely different than the problems addressed in level 2. In addition, it was with these pattern recognition problems that deep neural networks became prominent in the early 2000s which created what is currently meant when people say “AI.”
- I created an entirely new level, level 4, for the large language models that only recently emerged on the public stage. I put this on a new level for two reasons: a) the neural networks are much larger and require substantially more training that the pattern recognition problems, and b) large language models as an application are fundamentally different than the pattern recognition problems in level 3. Word patterns are much more complex, and the response (often called a “label” in the machine learning literature), which consists of a set of words, is much more varied (we would say the response is “stochastic”).
- Optimization, which is represented in levels 5 and 6, is fundamentally different from machine learning since it does not use a training dataset. Instead, optimization requires a model of the problem being optimized, along with well-defined decisions.
- Almost every use of “artificial intelligence” in the press today refers to the use of supervised machine learning where a training dataset is used to estimate a function so that it mimics the data. This might involve estimating demand as a function of price (level 2), identifying a picture as a flower (level 3), or “predicting” what someone might say based on a set of inputs (level 4). This raises a valid question: Can mimicry be true intelligence?
- We often associate true human intelligence with examples such as Einstein inventing general relativity or deriving E=mc\^2. Or perhaps it might be the invention of the silicon-based transistor to replace vacuum tubes. Articles in the press continually stress over the potential for AI to make strategic military decisions which requires skills from level 7. Clearly these are examples of very high levels of intelligence.
- The case can be made that most day-to-day human behavior, which certainly requires intelligence, represents a form of mimicry. While universities aspire to teach higher-level thinking, our educational system is founded on teaching students how to write well, how to solve well-structured problems, and what to do in certain situations. Medical schools and the medical literature are dominated by teaching “medical protocol” (that is, what to do in a specific situation). All of this is mimicry. From this background, a few students emerge who exhibit truly independent thinking.