A guided tour of the website
Sequential decision problems are a fantastically rich area, spanning virtually any problem setting where you are “trying to do better.” The SDA website was created to help people navigate this rich area, starting from basic questions such as “What is a decision” all the way through creating computer models to automate these processes.
This webpage represents a guided tour of the SDA website, helping newcomers to progress from basic starting material up through designing policies suited to specific situations. As you work down through the page, there are numerous links to various pages on the website. A useful strategy is to start by just reading this page, without clicking on the links. However, you will see that we are leaving a lot of information on the webpages within the website. If you click on the link to visit the page, be sure to return to this page to continue the tour.
We are going to conduct our tour using a series of passes:
- The first pass – Decisions and framing the problem This pass will introduce a first-time visitor to the most important elements of sequential decision problems, using minimal mathematics. Visitors will see examples of sequential decision problems, and how we approach the critical step of framing. For people working in an application domain who are not interested in developing models and automating the process of making decisions, this is a good stopping point.
- The second pass – The universal modeling framework Now we make stops at webpages which introduce more advanced material such as the universal modeling process, and incorporating the uncertainty of exogenous information processes. At this stage we have yet to address how to make a decision, which is done using a method we call a “policy,” but we have laid the foundation for how to evaluate policies. This material will involve some basic notation for modeling sequential decision problems at a high level.
- The third pass – Designing policies Next we turn to the problem of designing policies. In contrast with the academic literature which emphasizes sophisticated methods that are rarely used in practice, we are going to describe four classes of policies that include any method for making decisions. This allows us to identify the methods that are most widely used.
- The fourth pass – The “Ask Professor Powell” chatbot This has proven to be a popular feature of the SDA website. It is an “AI” chatbot trained on Professor Powell’s books, over 1000 pages of LinkedIn posts, and all the material on this website.
- The fifth pass – Stochastic search Stochastic search is an umbrella phrase that covers learning the best set of discrete inputs (such as the choice of policy type) or continuous parameters (such as the tunable parameters present in most policies). Stochastic search is an important class of sequential decision problems; I would argue that it is by far the most important class.
The first pass – Decisions and framing the problem
We start our first pass by visiting two topics under the menu Sequential decision problems. We begin with a brief overview of sequential decision problems, where we introduce some basic notation that we will return to from time to time:
Overview of sequential decision problems
It helps to have a problem setting in mind (more than one is even better). It is best to pick an application you are familiar with, ideally one that you have chosen or are experiencing directly. The next webpage should help with identifying some examples of sequential decision problems:
These applications should help illustrate the diversity of sequential decision problems. Despite the breadth of applications in this list, they are only scratching the surface.
We now investigate Modeling where we start with a brief introduction to modeling sequential decision problems:
The next stop is a big one. It is called Decisions, decisions, and it starts by highlighting the importance of decisions, and the surprising question of defining a decision, which appears to have been overlooked since the time of the Greek philosophers:
Next visit the second section which lists different types of decision settings. This section lists nine types of decision settings. The point of this list is to help with the process of identifying decisions:
We are now going to make our way to the important task of framing decision problems. Our approach to framing lays the foundation for thinking about any sequential decision problem. It uses no math, but it asks the questions that would be needed if we choose to use a math model, which is a prerequisite to using the computer. This step consists of identifying performance metrics, types of decisions, and sources of uncertainty:
Framing represents a major plateau, since it is an important (and overlooked) skill set even by itself, despite requiring no mathematics. There are countless models that suffer from improper framing, a byproduct of forcing applications into mathematical methods that are popular with academics.
Framing is an important skill for people working in an area of application. Each of the dimensions of framing can be immediately translated to a mathematical model (as we do in the second pass), but only if a model is needed. I claim that while framing is a critical first step to creating a computer model, it also helps people understand a problem even if they never develop a model.
The second pass – The universal modeling framework
At this point you have learned from the first pass:
- Some examples of sequential decision problems under your belt.
- A basic idea of what we mean by a sequential decision problem.
- An understanding of what we mean by a “decision.”
- A foundation in how to frame a sequential decision problem.
In the second pass, we are going to use the results of our problem framing to start building a formal model (yes, this means some math) of a sequential decision problem using what we call the universal modeling framework. Here we learn that any sequential decision problem can be modeled mathematically using five elements:
The universal modeling framework
What might be the most important characteristic of the UMF is what it does not include, which is any method for making a decision, known as a policy. The UMF introduces a fancy function \(X^{\pi}(S_t \mid \theta)\) where \(\pi = (f,\theta)\) carries the information that determines the structure of the policy (in “\(f\)”) while “\(\theta\)” carries any tunable parameters. We call this approach:
Model first, then solve
which means we model the problem and then design the policy (which “solves” the model).
Before we get to the task of designing policies, there are two important topics we need to cover on the modeling side:
-
State variables – This is a term that has been widely used in the modeling of sequential decision problems in fields with names like “optimal control” and “Markov decision processes (MDP),” but without providing a proper definition. “State variable” is simply another name for information, and we describe precisely what information is included. The section on state variables is at:
-
Modeling uncertainty – Decisions are one form of information (the “information we control”) that changes the state variable. The second is the exogenous information that comes from an external source which means we do not know (exactly) what will be coming.
As with framing, modeling uncertainty starts in English by describing the most important sources of uncertainty. We guide this process by starting with 12 ways that uncertainty can impact a model. Mathematical models of uncertainty can be quite sophisticated (if they are needed), but the first step is identifying the sources in English.
At this point, we have laid the foundation to evaluate a policy by simulating it, whether this is done in a computer simulator, or by watching how it works in the real world.
The third pass – Designing policies
Now that we understand how to evaluate a policy, we need to design one. The research literature is full of methods to make decisions over time as new information is arriving. The problem is that the literature is heavily biased toward sophisticated techniques (such as those based on Bellman’s equation) that are rarely used in practice.
It is important to always keep in mind: Sequential decision problems are everywhere! We are constantly making decisions, and these are almost always decisions being made over time, and we have been making decisions over the entire history of humanity using some method.
We are now going to take a tour of the four classes of policies (more accurately, meta-classes) which include any method for making decisions, including whatever you are already using to make decisions now. In fact, the case can be made that people already use all four classes, albeit in an ad hoc way, without any formal training. What is hard is replicating these policies on a computer.
The third pass will consist entirely of a tour of the menu item Policies, and we are going to focus on the first entry Overview which provides its own tour through the four classes of policies. So, start by clicking on
This section consists of six elements that provide an overview of the different classes of methods for making decisions.
- The four classes of policies – Here we list the four classes of policies, divided into two groups: the policy search group, which are the simplest and most widely used. These are functions that do not explicitly plan into the future, but are designed and tuned to work well over time. The second group explicitly plans into the future to help make better decisions now.
- Hybrids – When we design a policy, we are not limited to just one of the four classes. We often need to use combinations of two (sometimes more) of the classes at the same time.
- Simulating policies – We may end up with two different policies, and we are curious which works better. Or (and this is very common) we have to use tunable parameters that need to be tuned. For either question we need a way of evaluating the performance of a policy.
- Evaluating policies – We often assume that we have a single metric for evaluating the performance of a policy. In practice, we are often looking at up to eight different metrics, where only the first looks like a traditional objective function (using the language of deterministic optimization). Typically, the choice of the type of policy (e.g. which of the four classes) has to consider all of these attributes, whereas optimizing tunable parameters uses only the first.
- Optimizing over policies – Here we contrast how we approach stating a deterministic optimization problem, where we optimize over a decision vector \(x\), versus optimizing over policies, where we are searching for the best type of policy (the function \(f\)), and any tunable parameters \(\theta\).
- Choosing policies – While we may list four classes of policies, these are not equally popular. Here, we list policies based on usefulness, where the most useful policies fall in Category 1, which includes three different types of policies: PFAs, CFAs (which do not explicitly plan into the future), and deterministic DLAs (which do plan into the future). While the research literature often favors sophistication, the real-world is heavily biased toward simplicity. The image of the two ladders is designed to communicate the approach of starting with the simplest policy, and graduating toward more sophisticated policies as your model matures.
People who are interested in solving real problems always prefer the simplest policies, as they should. But keep in mind:
The price of simplicity is tunable parameters… and tuning is hard!
Once you have absorbed the material on the initial Policies page, it helps to choose one (or a few) applications and then start the process of learning more about each of the four classes by clicking on the menu items for each of the four classes under Policies. I recommend touring the policies in the following order:
- Policy function approximations (PFAs) – These are the simplest policies, and the only class which does not involve an imbedded optimization problem.
- Cost function approximations (CFAs) – CFAs involve an imbedded optimization, which is typically a simple sort where different choices are evaluated according to some metric. However, a CFA can be a deterministic linear, nonlinear or integer program, as might be used to assign machines to tasks.
- Deterministic direct lookahead approximations (Deterministic DLAs) – Deterministic DLAs are widely used to plan into the future, where we use point estimates of any uncertain quantity (Google Maps is an easy example for planning a path to the destination).
These three policies are likely to handle the vast majority of decision problems. However, if making a decision now requires planning for uncertainty in the future, keep reading:
- Stochastic direct lookahead approximations (Stochastic DLAs) – These are used when we really have to acknowledge the presence of uncertainty as we plan into the future. People who are familiar with decision trees will quickly recognize this class of policy, but decision trees represent just one of many approaches that might be used. The key is to remember that we are always using some approximation of our underlying stochastic problem.
And then there is the class of policies that is based on using Bellman’s equation:
- Policies based on value function approximations (VFAs) – This is where we approximate the downstream value of a decision using a device known as a value function approximation. The academic literature is strongly biased toward the use of Bellman’s equation, but as I like to say: “Bellman’s equation is a powerful strategy that works for a very small number of problems.” Note that I cover PFAs, CFAs and DLAs (deterministic and stochastic) using one chapter each in Reinforcement Learning and Stochastic Optimization, but I need five chapters to cover VFAs (Chapters 14 through 18).
A major motivation for using Bellman’s equation is that it dramatically simplifies making a decision now, since it avoids needing to explicitly plan into the future using a direct lookahead model. But estimating the downstream value of being in a state is hard.
The fourth pass – The “Ask Professor Powell” chatbot
At this point, you may start to have questions that are not being properly addressed by the information on the webpage. An easier path than purchasing the books and trying to find your answers there (which is unlikely), I recommend the “Ask Professor Powell” chatbot at
You may pose questions (using any of the major languages) that are related to the material in the webpage. The chatbot is trained on all of my books (written 2022 onward), over 1000 pages of LinkedIn posts on sequential decision problems, and all the material in this website. This material reflects over 40 years of research and the experience of applying these methods to countless applications (see, for example, the problems shown at Motivating applications).
It is not trained on the broader literature since the research literature is too biased toward techniques (such as those based on Bellman’s equation) that are favored by academics but rarely used in practice. As of this writing, I have seen it give responses that reflect a good understanding of the principles in the thousands of pages of training material.
While most questions are fairly short, I have seen users pose fairly complex questions that have produced multipage responses. At the bottom (left) of each response is a “Copy” button that copies your question and the response in a way that can be pasted into a nicely formatted Word document, or a text file.
You may ask questions, and then ask follow-up questions, and the chatbot will be able to continue a thread.
The chatbot can write out mathematics and can even write code. However, it is very unlikely that it would be able to solve a real problem given the subtleties of modeling. Please do not use any of the outputs of the chatbot in a production setting without understanding the concepts and verifying the recommendations.
The fifth pass – Stochastic search
Stochastic search is easily the most common form of sequential decision problem. It arises in two forms:
- Derivative-based stochastic search – We may have a set of continuous parameters that affect the performance of our policy, or any other continuous parameter (diameter of a wafer, price of a product, dosage of a drug, temperature of a manufacturing process). At the moment I do not have a webpage on this topic, but you can download Chapter 5, Derivative-based stochastic search, in Reinforcement Learning and Stochastic Optimization. Pay special attention to the algorithm called SPSA (see section 5.4.4) which is a powerful strategy for doing derivative-based stochastic search when the parameters form a vector, and where you do not have access to an explicit formula for the derivatives (gradient).
- Derivative-free stochastic search – These problems arise when there is a set of discrete choices and we want to make the choice that is “best” according to some metric, but we are not sure about the performance of the choices. The problem is illustrated below. I have covered this problem under the label of “optimal learning” but it has been studied under names such as “multiarmed bandit problem,” “Bayesian optimization,” “ranking and selection,” “design of experiments” or “intelligent trial-and-error.”
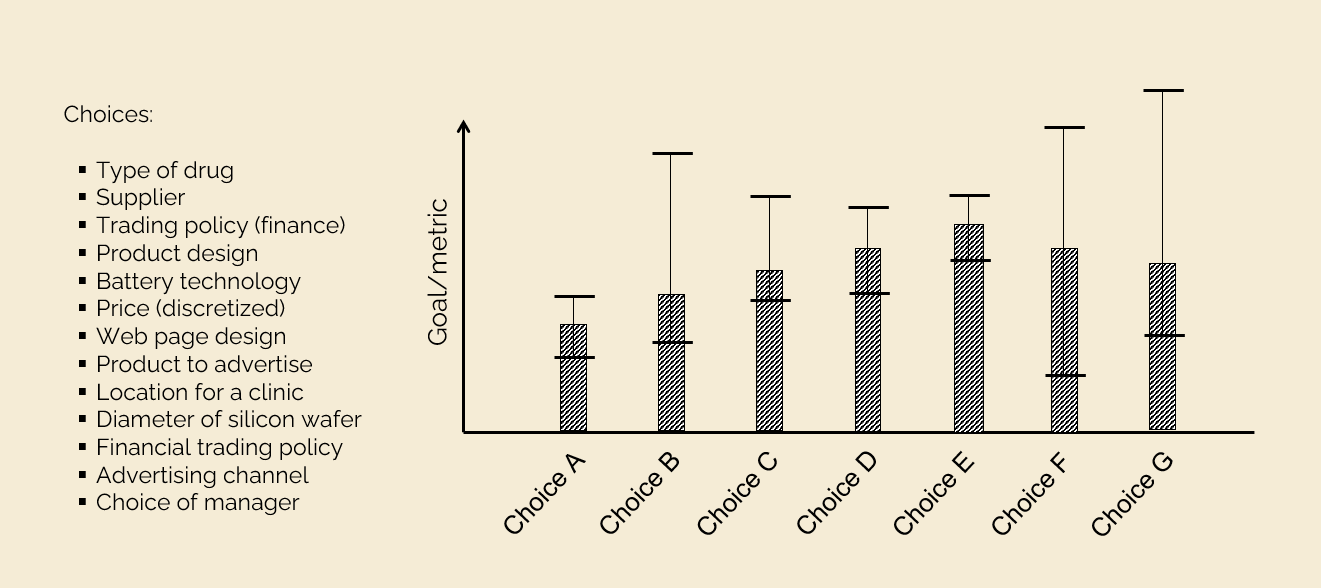
Derivative-free stochastic search is a sequential decision problem where the state variable consists purely of the beliefs about the performance of each choice. Chapter 7 of Reinforcement Learning and Stochastic Optimization deals with this topic in depth, illustrating in the process all four classes of policies, although only two are widely used. We describe both on the SDA website.
The SDA website covers this topic under the heading of optimal learning which can be accessed at:
The page has a number of headings. Below is a brief summary of each, and you can click on any of the headings and go to the corresponding webpage.
- Classes of optimal learning problems – Optimal learning problems, especially when stated as a “multi-armed bandit problem,” is often posed as a set of discrete choices (such as products to advertise on a webpage) with unknown values (the likelihood that a user might purchase the product). In fact, optimal learning problems can be described along multiple dimensions such as:
- Cost of observing performance (inexpensive, such as an ad-click, to expensive, such as running an experiment in the field spanning several weeks or more).
- Is there a budget constraint limiting the number of experiments?
- How are the beliefs represented? Discrete (lookup table) or a parametric belief model? Are the beliefs independent or correlated? Are the metrics static or evolving over time?
- Whether we are experimenting in an offline environment (lab or simulator) or in the field.
- Do the experiments (observations) require managing physical resources?
- The communities of optimal learning – This is a list of the various communities that study this problem under different names.
- A bit of history – Completely optional, but some enjoy learning about how a field unfolded.
- The knowledge gradient for offline learning – The knowledge gradient uses a (stochastic) direct lookahead approximation to estimate the value of information from an observation made now. It was originally developed in the context of experiments where we have a budget for running experiments in an offline setting. This section derives the knowledge gradient for this setting.
- The knowledge gradient for online learning – There are many settings where we need to learn in the field, which means we have to incur the costs (and benefits) of experiments while we learn. Here we show that the knowledge gradient for the online setting is a simple function of KG for offline.
-
UCB policies for offline and online learning – Upper confidence bounding policies became very popular in computer science because they are simple and lend themselves to proving regret bounds. One example of a UCB policy is
\[X^{UCB\text{-}off}\left(S_t \mid \theta\right) = \text{argmax}_x\left(\overline{\mu}_{tx} + \theta\,\overline{\sigma}_{xt}\right)\]where
\(\overline{\mu}_{tx} =\) Estimate of the performance of choice \(x\) at time \(t\) (or after \(t\) experiments).
\(\overline{\sigma}_{xt} =\) Standard deviation of \(\overline{\mu}_{tx}\).
\(\theta =\) a tunable parameter.
UCB policies are very simple (trivial even), but as I have said before: “the price of simplicity is tunable parameters… and tuning is hard.” These policies were originally developed for online learning, but they can be tuned for either online or offline settings. At the same time, tuning picks up any other problem characteristics such as the level of noise in the experiments, the budget, and the nature of the belief model (e.g. are there correlated beliefs).
- KG vs. UCB and the problem of tuning – UCB policies are a form of cost function approximation (CFA), since they require solving an optimization problem (in the form of the sorting over the adjusted values of each choice), with a tunable parameter. KG, on the other hand, is a form of stochastic DLA. KG is clearly more complex, but one benefit is that it does not have any tunable parameters.
- A video application of UCB and KG – Here we include a video illustrating the use of UCB policies and the knowledge gradient for the problem of tuning a policy governing how much cash to keep on hand for a mutual fund. I call this “learning while doing” and it suggests a general strategy for tuning operating rules.
- The knowledge gradient – the original research – The knowledge gradient is based on an extensive body of research that came from CASTLE Lab, starting with the work of Peter Frazier during the period 2005–2008. His work was then further developed by five or six subsequent Ph.D. students and a post-doc.